Excel’s text file formats
25 August 2017
At the face of it, a text file would seem to be the simplest thing, just a series of characters. Trying to save an Excel file as a text file reveals that things are a bit more complicated. At first, there are what looks like a bewildering number of options. These options come from three main sources: delimiters, line endings, and encodings.
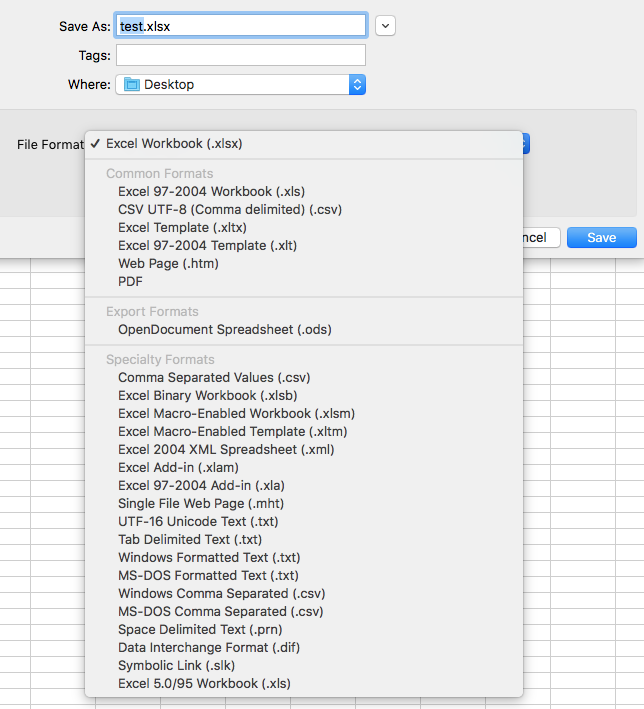
Delimiters
When exporting a table from Excel, there are two main options for how columns will be specified in the text file, and these are known as delimiters. File formats that use a .csv suffix will have the columns separated by commas, and those with a .txt suffix use tabs. Some applications use other delimiters, such as semicolons or spaces. Opening a file in a text editor should make it clear what is being used to delimit columns. At least on macOS, Excel offers four ways to export a .csv file: CSV UTF-8 (Comma delimited) (.csv), Comma Separated Values (.csv), Windows Comma Separated (.csv), and MS-DOS Comma Separated (.csv). Likewise, the macOS version of Excel provides four ways of exporting a .txt file: UTF-16 Unicode Text (.txt), Tab Delimited Text (.txt), Windows Formatted Text (.txt), and MS-DOS Formatted Text (.txt). It is important to realize that, regardless of their suffix, all of these are plain-text files that can be read and modified in any text editor.
Line endings
Some of these options arise from the ways in which the end of a line is specified in a text file. How early computers handled what to do at the end of a line, and what character to put there, stemmed from typewriters and printers of the day. On a typewriter, one could simply move the carriage to the left, which would return the typing point to the beginning of the same line, and this was known as a Carriage Return (CR). One could also advance to the next line, and this was known as Line Feed (LF). On a typewriter, you would typically do both simultaneously (CR LF), but you could choose just one.
In the early days of Mac and DOS computers, different operating systems used different (invisible) characters at the ends of lines of data. Unix systems used LF, Mac used CR, and DOS used CR LF. Later, Windows continued using CR LF, but MacOS switched to LF once it became a UNIX operating system (starting with OS X 10.0). These line endings matter because software may not have be written to recognize all of these as valid. For example, some Windows applications cannot properly read .txt files created on a Mac, and vice versa. Applications are better at recognizing these variations today than they were a decade ago.
Some of the file options in Excel reflect the different line endings to ensure Mac-Windows compatibility. Of the four .txt file formats on the MacOS version of Excel, two use CR (MS-DOS Formatted Text and Tab Delimited Text) and two use CR LF (UTF-16 Unicode Text and Windows Formatted Text). Of the four .csv file formats, one uses CR (CSV UTF-8) and three use CR LF (Comma Separated Values, MS-DOS Comma Separated, and Windows Comma Separated).
Encodings
Encodings are the final and most complex reason for this profusion of text-file formats. In memory or on a drive, computer files are not characters or symbols, but merely a series of magnetic bits that exist in only one of two states, which can be symbolized as 1 or a 0. Eight of these bits is called a byte, and in the earliest computer systems, a byte corresponded to a character. Seven of the bits in a byte were used to encode a character, and the eighth bit was used to check for errors. Thus, if each bit has only two possible states, seven of these bits provide 27 or 128 possibilities. In other words, this encoding (called ASCII) provided for only 128 characters, enough to cover upper-case and lower-case letters, numbers, some punctuation, and a few other special-purpose characters.
As subsequent computers needed to represent more characters, such as vowels with umlauts and accents, other encoding systems were created. Early Macs used the Mac OS Roman encoding, which supported supported 256 characters (called Mac OS Roman), and DOS and Windows systems had their own encodings. More recently, newer encodings allow for far more characters and are known as UNICODE. The simplest of these is still 8 bit, but 16-bit and 32-bit versions also exist, which allow for vastly more characters (65,536 and 4 billion). From this, we now have the ability to display characters in any alphabet or language, plus all of the emoji symbols.
Encoding is critical because it specifies how bits get converted into human-readable characters. If you open a file encoded in one format (say, UTF-16) in a different format (say, ASCII), it will likely be gibberish. Most Excel files use UTF-8, although one (CSV UTF-8) uses a variant (called UTF-8 with BOM) that may make them unreadable in some applications. One Excel file type uses UTF-16, and that is obvious from its name: UTF-16 Unicode Text.
The final complication to encodings is the order in which bits within a byte are read, with the two options being little-endian and big-endian. The BOM, or Byte-Order Mark, mentioned above specifies which order a file uses. If a file does not include a BOM, an assumption is made about the byte order. If the assumption is incorrect, the text will look like nonsense characters.
Investigating text file format
A good text editor makes it simple to determine delimiters, line endings, and encodings. Delimiters are often obvious on inspection, although distinguishing spaces and tabs can be more difficult. Most text editors have an option to display special characters for invisible characters (spaces, tabs, line feeds, carriage returns, etc.) that can remove any doubt about what characters are in a text file.
Line endings and encodings are often easy to check. For example, in BBEdit, the current line endings and encodings are displayed at the bottom of each text window. For example, this text file has an encoding of Unicode (UTF-8) and Unix-style line endings (LF). These values can be changed, by clicking on these values and selecting from the pull-up menus.

Which one should I use?
In most cases, it won’t matter which file format you choose when you export your data from Excel, as you can use most of them in R without any changes. The sole Excel format in UTF-16 (UTF-16 Unicode Text) is the only one that I could not import into R. All the others could be read easily and correctly, with the delimiter being the only thing specified. R interpreted the encoding and line endings correctly, although the only characters I used were limited to the relatively small ASCII character set (upper-case and lower-case letters, numbers, and basic punctuation).
Excel’s UTF-16 file could be opened in BBEdit, and then saved with a Unicode (UTF-8) encoding, after which it could be imported correctly into R. If a colleague shares a UTF-16 file with you, remember that you can convert it to UTF-8 in your text editor.
When importing files from Excel, be aware that apostrophes will generally cause problems when you try to import them. One solution is to not use apostrophes or quotes in your Excel file; another is to check the quote parameter of read.table(). Also be aware that Excel sometimes does not add a return after the final line of data and that can prevent R from reading the file. The simplest solution is to open the file in a text editor and add a return character after the final line of data.
Comments
Comments or questions? Contact me at stratum@uga.edu
